
Page 109 - 고등학교 인공지능 기초
P. 109
생각
확장하기 강화 학습이란?
2015년 탄생한 알파고는 2016년 이세돌과의 대결에서 4승 1패로 승리를 거두면서 유명세
를 탄 이후 2017년 공개된 알파고 제로는 인간의 기보 입력 없이 자체 학습만 진행하여 학습 시
작 36시간 만에 알파고의 수준을 능가하였다. 알파고 제로의 학습에 사용된 원리는 ‘강화 학습
(reinforcement learning)’이다.
기계학습에는 지도학습, 비지도학습뿐만 아니라 강화 학습이 있다. 강화 학습은 목적으로 하는
보상을 최대화 또는 최소화하는 방식으로 에이전트를 학습시켜 환경에 반응하게 하는 학습 방식이
다. 즉, 강화 학습은 보상(reward)이 발생하는 문제에 대하여 각 상태(state)에서 에이전트가 행동
(action)을 결정하도록 하는 기계학습 방법이다. 게임은 에이전트의 행동 결과가 점수 보상으로 바
로 이어지기 때문에 강화 학습으로 학습시키기에 적합한 분야이다.
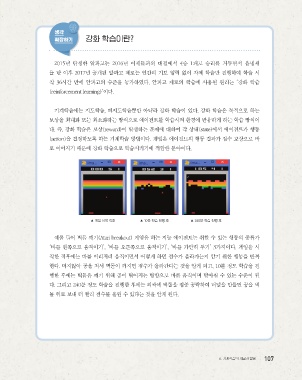
▲ 게임 시작 직후 ▲ 10분 학습 진행 후 ▲ 240분 학습 진행 후
예를 들어 벽돌 깨기(Atari breakout) 게임을 하는 지능 에이전트는 취할 수 있는 행동의 종류가
‘바를 왼쪽으로 움직이기’, ‘바를 오른쪽으로 움직이기’, ‘바를 가만히 두기’ 3가지이다. 게임을 시
작한 직후에는 바를 이리저리 움직이면서 어떻게 하면 점수가 올라가는지 알기 위한 행동을 반복
한다. 머지않아 공을 쳐서 벽돌이 깨지면 점수가 올라간다는 것을 알게 되고, 10분 정도 학습을 진
행한 후에는 벽돌을 깨기 위해 공이 떨어지는 방향으로 바를 움직이며 받아칠 수 있는 수준이 된
다. 그리고 240분 정도 학습을 진행한 후에는 외곽에 벽돌을 집중 공략하여 터널을 만들면 공을 벽
돌 위로 보내 더 빨리 점수를 올릴 수 있다는 것을 알게 된다.
107
6. 기계학습의 개념과 활용