
Page 193 - 고등학교 인공지능 기초
P. 193
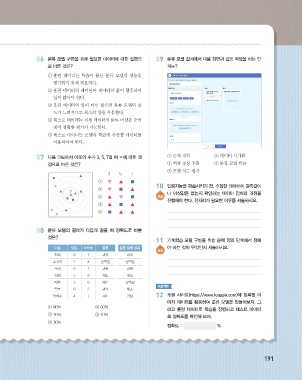
06 분류 모델 구현을 위해 필요한 데이터에 대한 설명으 09 분류 모델 설계에서 다음 화면과 같은 작업을 하는 단
로 바른 것은? 계는?
① 훈련 데이터는 학습이 끝난 분류 모델의 성능을
평가하기 위해 필요하다.
② 훈련 데이터의 레이블과 데이터의 값이 편중되어
있지 않아야 한다.
③ 훈련 데이터의 양이 너무 많으면 분류 모델의 속
도가 느려지므로 최소의 양을 사용한다.
④ 테스트 데이터는 전체 데이터의 80% 이상을 준비
해야 정확한 평가가 가능하다.
⑤ 테스트 데이터는 모델의 학습에 사용한 데이터를
이용하여야 한다.
07 다음 그림에서 이웃의 수가 3, 5, 7일 때 ●에 대한 결 ① 문제 정의 ② 데이터 시각화
정으로 바른 것은? ③ 핵심 속성 추출 ④ 분류 모델 학습
⑤ 모델 성능 평가
3 5 7
① 10
② 인공지능을 학습시키기 전, 수집한 데이터에 결측값이
? 나 이상값은 없는지 확인하는 데이터 전처리 과정을
③ 서술
진행해야 한다. 전처리가 필요한 이유를 서술하시오.
④
⑤
08 분류 모델의 결과가 다음과 같을 때 정확도로 바른
것은?
11 기계학습 모델 구현을 위한 문제 정의 단계에서 정해
이름 당도 아삭함 종류 분류 모델 결과 야 하는 것이 무엇인지 서술하시오.
서술
참외 8 7 과일 과일
소시지 2 4 단백질 단백질
수박 9 7 과일 과일
양파 5 8 채소 채소
배추 3 6 채소 단백질
프로젝트
멜론 9 2 과일 채소
12 캐글 사이트(https://www.kaggle.com)에 등록된 이
양배추 4 7 채소 과일
미지 데이터를 활용하여 분류 모델을 만들어보자. 그
① 80% ② 60%
리고 훈련 데이터로 학습을 진행하고 테스트 데이터
③ 50% ④ 40%
로 정확도를 확인해 보자.
⑤ 30%
정확도 : %
191